برای کاهش تاثیر خطاهای تصادفیلازم است این مقدار چندین بار اندازه گیری شود. فرض کنید مقداری x را اندازه می گیریم. در نتیجه اندازه گیری ها، مقادیر زیر را به دست آوردیم:
x 1، x 2، x 3، ... x n. (1.4)
این سری از مقادیر x را نمونه می نامند. با داشتن چنین نمونه ای می توانیم نتیجه اندازه گیری را ارزیابی کنیم. ما مقداری را نشان خواهیم داد که چنین تخمینی خواهد بود. اما از آنجایی که این مقدار ارزیابی اندازه گیری، مقدار واقعی کمیت اندازه گیری شده را نشان نخواهد داد، لازم است خطای آن برآورد شود. بیایید فرض کنیم که می توانیم تخمین خطا Δx را تعیین کنیم. در این صورت می توانیم نتیجه اندازه گیری را در فرم بنویسیم
x = ± Δx. (1.5)
از آنجایی که مقادیر تخمینی نتیجه اندازهگیری و خطای Δx دقیق نیستند، ثبت نتیجه اندازهگیری باید با نشانهای از قابلیت اطمینان آن همراه باشد P. قابلیت اطمینان یا احتمال اطمینان به عنوان احتمال درک میشود که معنی واقعیمقدار اندازه گیری شده در بازه ای است که با ورودی (3) نشان داده شده است. به خود این فاصله، فاصله اطمینان می گویند.
به عنوان مثال، هنگام اندازه گیری طول یک قطعه خاص، نتیجه نهایی را در فرم نوشتیم
ل= (0.02 ± 8.34) میلی متر،(P = 0.95). (1.6)
این بدان معنی است که از 100 شانس، 95 مورد وجود دارد که مقدار واقعی طول قطعه در بازه 8.32 تا 8.36 باشد. میلی متر.
بنابراین، وظیفه این است که با توجه به نمونهای از اندازهگیریها، تخمینی از نتیجه اندازهگیری، خطای آن Δx و قابلیت اطمینان P را پیدا کنیم.
این مشکل را می توان با استفاده از نظریه احتمال و آمار ریاضی.
در بیشتر موارد، خطاهای تصادفی از قانون توزیع نرمال که توسط گاوس ایجاد شده است پیروی می کنند. قانون توزیع خطای نرمال با فرمول بیان می شود
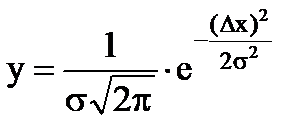 , (1.7)
, (1.7)
جایی که Δx انحراف از مقدار واقعی است.
σ – میانگین مربعات خطای واقعی؛
σ 2 - پراکندگی، که مقدار آن گسترش متغیرهای تصادفی را مشخص می کند.
همانطور که از فرمول مشخص است، تابع y(x) دارد حداکثر مقداربرای x=0، علاوه بر این، زوج است.
| y |
| ایکس |
| Δx 1 |
| Δx 2 |
| -Δx 1 |
| -Δx 2 |
شکل 1.4. منحنی توزیع نرمال گاوسی
شکل 1.4 نمودار این تابع را نشان می دهد. مساحت شکل محصور بین منحنی، محور Δx و دو مختصات از نقاط Δx 1 و Δx 2 (منطقه سایه دار) از نظر عددی برابر است با احتمال سقوط هر نمونه در بازه (Δx 1,Δx). 2).
از آنجایی که منحنی به طور متقارن حول ارتجاع توزیع شده است، می توان استدلال کرد که خطاهایی با قدر مساوی اما علامت مخالف به یک اندازه محتمل هستند. و این امکان در نظر گرفتن مقدار متوسط همه عناصر نمونه را به عنوان ارزیابی نتایج اندازه گیری می کند:
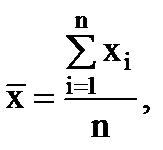 (1.8)
(1.8)
که در آن n تعداد اندازه گیری ها است.
اگر n اندازه گیری در شرایط یکسان انجام شود، بیشترین مقدار مقدار احتمالیکمیت اندازه گیری شده مقدار متوسط (حساب) آن خواهد بود. کمیت به مقدار واقعی x و کمیت اندازه گیری شده به صورت n → ∞ تمایل دارد.
ریشه میانگین مربعات خطای یک نتیجه اندازه گیری فردی، کمیت است
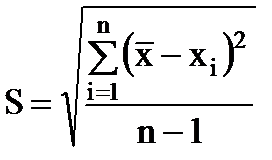 (1.9)
(1.9)
این خطای هر اندازه گیری فردی را مشخص می کند. همانطور که n → ∞ S به حد ثابت σ تمایل دارد:
σ = lim S.
n → ∞ (1.10)
با افزایش σ، گسترش قرائت ها افزایش می یابد، به عنوان مثال. دقت اندازه گیری کمتر می شود.
ریشه میانگین مربعات خطای میانگین حسابی مقدار است
 (1.11)
(1.11)
این قانون اساسی افزایش دقت با افزایش تعداد اندازه گیری ها است.
خطا مشخص کننده دقتی است که با آن مقدار متوسط مقدار اندازه گیری شده به دست می آید. نتیجه به صورت زیر نوشته می شود:
x = ± Δx. (1.12)
این تکنیک محاسبه خطا را می دهد نتایج خوب(با قابلیت اطمینان 0.68) فقط در موردی که همان مقدار حداقل 30 - 50 بار اندازه گیری شده باشد.
در سال 1908، ویلیام سیلی گوست، آماردان مشهوری که بیشتر با نام مستعار دانشجو شناخته میشود، نشان داد که رویکرد آماری حتی با تعداد کمی اندازهگیری معتبر است. توزیع Student برای تعدادی اندازه گیری n ∞ به یک توزیع گاوسی تبدیل می شود و برای تعداد کمی با آن متفاوت است.
برای محاسبه خطای مطلق با تعداد کم اندازه گیری، ضریب خاصی بسته به قابلیت اطمینان P و تعداد اندازه گیری n معرفی می شود که ضریب Student t نامیده می شود. هنگام معرفی این ضریب
با حذف توجیه نظری مقدمه آن، متذکر می شویم که
Δx t = t، (1.13)
که در آن Δx t خطای مطلق برای یک احتمال اطمینان معین است. – ریشه میانگین مربعات خطای میانگین حسابی.
ضرایب دانشجو در پیوست 1 آورده شده است.
از آنچه گفته شد چنین است:
1. مقدار خطای ریشه میانگین مربع امکان محاسبه احتمال سقوط مقدار واقعی مقدار اندازه گیری شده در هر بازه ای نزدیک به میانگین حسابی را فراهم می کند.
2. به عنوان n → ∞ → 0، i.e. فاصله زمانی که مقدار واقعی x و با احتمال معینی در آن قرار دارد، با افزایش تعداد اندازهگیریها، به سمت صفر میرود. به نظر می رسد که با افزایش n می توان با هر درجه دقت به نتیجه رسید. با این حال، دقت به طور قابل توجهی افزایش می یابد تا زمانی که خطای تصادفی با خطای سیستماتیک قابل مقایسه شود. افزایش بیشتر در تعداد اندازه گیری ها غیر عملی است، زیرا دقت نهایی نتیجه فقط به خطای سیستماتیک بستگی دارد. با دانستن بزرگی خطای سیستماتیک، تعیین مقدار مجاز خطای تصادفی دشوار نیست، مثلاً آن را برابر با 10٪ از خطای سیستماتیک در نظر بگیرید. با تنظیم یک مقدار P معین برای فاصله اطمینان انتخاب شده به این روش (به عنوان مثال، P = 0.95)، یافتن تعداد مورد نیاز اندازه گیری که تأثیر کوچکی از خطای تصادفی را بر دقت نتیجه تضمین می کند، دشوار نیست.
برای انجام این کار، استفاده از جدول ضمیمه 2 راحت تر است، که در آن فواصل به کسری از مقدار σ داده شده است، که اندازه گیری دقت یک آزمایش داده شده در رابطه با خطاهای تصادفی است.
برخی از ضرایب Student، با یک ستون برجسته برای قابلیت اطمینان P = 95٪، در جدول 1.6 آورده شده است.
ضرایب دانش آموز جدول 1.6
| nآر | 0,9 | 0,95 | 0,999 |
| 6,31 2,92 2,35 2,13 2,02 1,94 1,89 1,86 1,83 | 12,7 4,30 3,18 2,78 2,57 2,45 2,36 2,31 2,26 | 636,6 31,6 12,9 8,61 6,37 5,96 5,41 5,04 4,78 | |
| ∞ | 1,96 |
هنگام پردازش نتایج چندین اندازه گیری مستقیم، ترتیب عملیات زیر را انجام دهید:
1. نتیجه هر اندازه گیری را در جدول بنویسید.
2. میانگین n اندازه گیری را محاسبه کنید
 (1.14)
(1.14)
3. خطای یک اندازه گیری فردی را بیابید
 (1.15)
(1.15)
4. مجذور خطاهای اندازه گیری های فردی را محاسبه کنید
(Δx 1) 2 , (Δx 2) 2 , ... , (Δx n) 2 . (1.16)
5. ریشه میانگین مربعات خطای میانگین حسابی را تعیین کنید
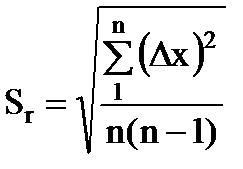 . (1.17)
. (1.17)
6. مقدار قابلیت اطمینان (معمولا P = 0.95) را تنظیم کنید.
7. ضریب Student t را برای پایایی معین P و تعداد اندازه گیری های انجام شده n تعیین کنید.
8. فاصله اطمینان (خطای اندازه گیری) را پیدا کنید
Δx t = · t. (1.18)
اگر بزرگی خطا در نتیجه اندازه گیری Δx قابل مقایسه با بزرگی خطای دستگاه Δx p باشد، آنگاه حد فاصله اطمینان را در نظر بگیرید:
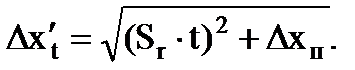 (1.19)
(1.19)
اگر یکی از خطاها سه بار یا بیشتر از دیگری کوچکتر است، خطای کوچکتر را کنار بگذارید.
9. نتیجه نهایی را در فرم بنویسید
 . (1.20)
. (1.20)
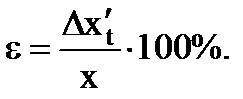 (1.21)
(1.21)
اجازه دهید با استفاده از یک مثال عددی کاربرد فرمول های فوق را در نظر بگیریم.
مثال.قطر d میله با میکرومتر اندازه گیری شد (خطای اندازه گیری سیستماتیک 0.005 است. میلی متر). نتایج اندازه گیری را در ستون دوم جدول وارد می کنیم، پیدا می کنیم، و در ستون سوم این جدول تفاوت ها را می نویسیم و در چهارم - مربع های تفاوت آنها را می نویسیم (جدول 1.7).
جدول 1.7
| n | د، میلی متر | ||
| 4.02 | + 0.01 | 0.0001 | |
| 3.98 | - 0.03 | 0.0009 | |
| 3.97 | - 0.04 | 0.0016 | |
| 4.01 | + 0 .00 | 0.0000 | |
| 4.05 | + 0.04 | 0.0016 | |
| 4.03 | + 0.02 | 0.0004 | |
| Σ | 24.06 | – | 0.0046 |
![]() (1.22)
(1.22)
با تنظیم پایایی بر روی 0.95 = P، با استفاده از جدول ضرایب Student برای شش اندازه گیری، t = 2.57 را پیدا می کنیم. خطای مطلق را می توان با استفاده از فرمول (10) پیدا کرد.
Δd = 0.01238 2.57 = 0.04 میلی متر. (1.24)
بیایید خطاهای تصادفی و سیستماتیک را با هم مقایسه کنیم:
بنابراین δ = 0.005 میلی متررا می توان دور انداخت.
نتیجه نهایی را به شکل زیر می نویسیم:
d = (0.04 ± 4.01) میلی متردر P = 0.95. (1.26)
اگر کمیت اندازه گیری شده آتابعی از چندین متغیر است: آ= اف(ایکس, y,..., تی), که خطای مطلقنتیجه اندازه گیری های غیر مستقیم
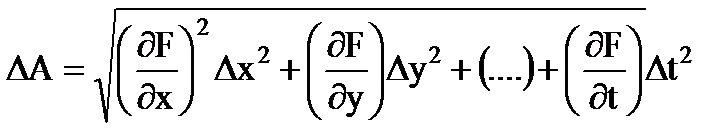 (1.29)
(1.29)
خطاهای نسبی جزئی اندازه گیری غیرمستقیم توسط فرمول ها تعیین می شود
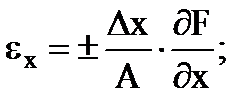
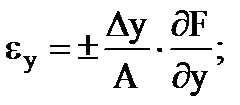 …. و غیره (1.30)
…. و غیره (1.30)
خطای مربوطهنتیجه اندازه گیری
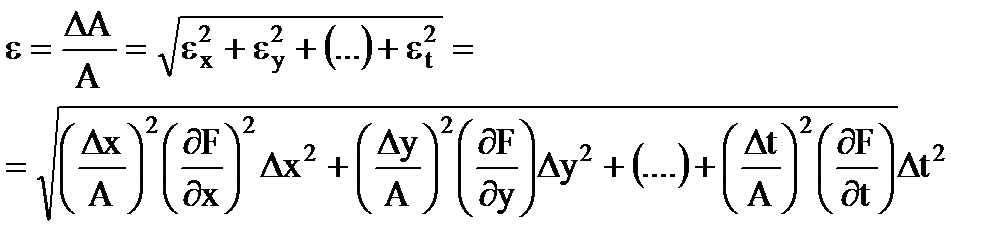 (1.31)
(1.31)
خطای فاحش (از دست دادن)- این یک خطای تصادفی در نتیجه مشاهدات فردی است که در یک سری اندازه گیری گنجانده شده است، که برای شرایط داده شده، به شدت با سایر نتایج این سری متفاوت است. آنها معمولاً به دلیل خطاها یا اقدامات نادرست اپراتور (وضعیت روانی فیزیولوژیکی او، خواندن نادرست، خواندن قرائت از مقیاس ابزار مجاور، اشتباهات در ضبط یا محاسبات، روشن کردن نادرست دستگاه ها یا نقص در عملکرد آنها و غیره) ایجاد می شوند. دلیل احتمالیاز دست دادن همچنین می تواند به دلیل تغییرات شدید کوتاه مدت در شرایط اندازه گیری رخ دهد. اگر خطاها در طول فرآیند اندازه گیری شناسایی شوند، نتایج حاوی آنها دور ریخته می شوند. با این حال، اغلب خطاها تنها در طول پردازش نهایی نتایج اندازه گیری با استفاده از معیارهای آماری خاص شناسایی می شوند.
بسته به علل وقوع، خطاهای ابزاری، روش شناختی و ذهنی متمایز می شوند.
خطای ابزاری- خطای ذاتی در خود ابزار اندازه گیری، به عنوان مثال. ابزار یا مبدلی که اندازه گیری با آن انجام می شود. دلایل خطای ابزاری ممکن است نقص در طراحی ابزار اندازه گیری، نفوذ باشد محیطدر مورد مشخصات آن، تغییر شکل یا سایش قطعات دستگاه و غیره.
خطای روش شناختیبه دلیل نقص روش اندازه گیری ظاهر می شود. اختلاف بین کمیت اندازه گیری شده و مدل آن که در طول توسعه ابزار اندازه گیری اتخاذ شده است. تأثیر ابزار اندازه گیری بر جسم اندازه گیری و فرآیندهای رخ داده در آن. ویژگی های متمایز کننده خطاهای روش شناختیاین است که آنها را نمی توان در اسناد نظارتی و فنی برای ابزار اندازه گیری نشان داد، زیرا آنها به آن وابسته نیستند، اما باید توسط اپراتور در هر مورد خاص تعیین شوند.
خطای ذهنی (شخصی).اندازه گیری به دلیل خطای اپراتور در خواندن قرائت در مقیاس های ابزار اندازه گیری و نمودارهای ابزار ضبط است. آنها به دلیل وضعیت اپراتور، موقعیت او در حین کار، نقص حواس و ویژگی های ارگونومیک ابزار اندازه گیری ایجاد می شوند. ویژگیهای خطای ذهنی بر اساس مقدار اسمی نرمال شده تقسیم مقیاس ابزار اندازهگیری (یا کاغذ نمودار ابزار ضبط)، با در نظر گرفتن توانایی «اپراتور متوسط» برای درونیابی در داخل تعیین میشود. تقسیم مقیاس این خطاها با بهبود ابزارها کاهش می یابد، به عنوان مثال: استفاده از یک اشاره گر نور در ابزارهای آنالوگ، خطای ناشی از اختلاف منظر را حذف می کند. اختلاف منظر(از یونانی parállaxis - انحراف)، تغییر قابل مشاهده در موقعیت نسبی اشیاء به دلیل حرکت چشم ناظر) استفاده از بازخوانی دیجیتال خطای ذهنی را حذف می کند.
خطای اندازه گیری عینی- خطایی که به ویژگی های شخصی شخصی که اندازه گیری می کند بستگی ندارد.
با نفوذ شرایط خارجیخطاهای اصلی و اضافی دستگاه اندازه گیری را تشخیص دهید.
خطای اصلی ابزار اندازه گیری است، تعریف شده در شرایط عادیکاربرد آن برای هر ابزار اندازه گیری، شرایط عملیاتی در اسناد نظارتی و فنی مشخص شده است - مجموعه ای از مقادیر تأثیرگذار (دمای محیط، رطوبت، فشار، ولتاژ، فرکانس منبع تغذیه و غیره) که تحت آن خطای آن نرمال می شود (مقدار تأثیرگذار). است کمیت فیزیکی، توسط یک ابزار اندازه گیری مشخص اندازه گیری نمی شود، بلکه بر نتایج آن تأثیر می گذارد).
اضافی نامیده می شودخطای یک ابزار اندازه گیری ناشی از انحراف هر یک از کمیت های تأثیرگذار، یعنی. خطای اضافیکه باعث افزایش خطای کلی دستگاه می شود، در صورتی رخ می دهد که دستگاه در شرایطی غیر از حالت عادی کار کند.
بسته به ماهیت تغییر در بزرگی خطا هنگام تغییر مقدار اندازه گیری شده، خطاها تقسیم می شوند. به جمع و ضرب.
خطاهای افزایشیناشی از تغییر در مشخصات استاتیکی دستگاه به بالا یا پایین (به راست یا چپ)، به عنوان مثال به دلیل تغییر مقیاس دستگاه (دریفت صفر)، اصطکاک در تکیه گاه ها و غیره. خطای افزایشی به مقدار کمیت اندازه گیری شده x بستگی ندارد، یعنی. در کل مقیاس دستگاه ثابت است.
خطاهای افزایشی در اکثر ابزارهای آنالوگ غالب است.
خطاهای ضربیبه دلیل خطاهایی در تنظیم ضریب انتقال k مشخصه استاتیک y = kx ایجاد می شود. خطای ضرب به مقدار کمیت اندازه گیری شده بستگی دارد و تا انتهای مقیاس ابزار افزایش می یابد.
خطای ضربی (زمانی که به صورت خطای مطلق بیان می شود) متناسب با مقدار کمیت اندازه گیری شده است.
خطاهای ضربی در دستگاه های مربوط به مبدل های مقیاس بندی (شنت ها، مقاومت های اضافی، تقویت کننده ها، تقسیم کننده ها، ترانسفورماتورها و غیره) غالب است.
دستگاه هایی هستند که خطاهای افزایشی و ضربی آنها قابل مقایسه هستند. این دسته از دستگاه ها شامل دستگاه های دیجیتال می شود.
خطاهای اندازه گیری تصادفی به دلیل تأثیر همزمان چندین کمیت مستقل بر روی شی اندازه گیری ایجاد می شود که تغییرات آنها دارای ماهیت نوسانی است. خطای تصادفی ابزار اندازه گیری نیز سهم خاصی در خطای اندازه گیری تصادفی دارد.
فرض می کنیم که جزء سیستماتیک خطای اندازه گیری مستثنی شده و خطای تصادفی به عنوان یک متغیر تصادفی کاملاً است.
با چگالی توزیع احتمال مشخص می شود (در غیر این صورت، چگالی احتمال) که در آن تابع توزیع است. بنابراین، این مقدار عددی نیست که تعیین می شود خطای تصادفی، اما فقط این احتمال وجود دارد که در یک بازه زمانی مشخص باشد یا از مقدار معینی تجاوز نکند. اگر قانون توزیع شناخته شده باشد، احتمال یافتن یک خطای تصادفی در یک بازه معین از تا طبق فرمول مشخص می شود.
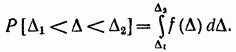
الگوی تغییرات خطای تصادفی را می توان از طریق مشاهدات مکرر مقادیر آن و پردازش آماری نتایج مشاهدات تعیین کرد.
![]()
برنج. 2-1. چگالی احتمال خطاهای تصادفی تحت قانون توزیع نرمال
این کار پر زحمت و پر زحمت با اندازه گیری های دقیق انجام می شود و شامل بررسی انطباق داده های به دست آمده با توزیع مورد انتظار بر اساس معیارهایی است.
نوسانات کمیت های تأثیرگذار نیز تصادفی هستند و با قوانین توزیع خاص خود (یکنواخت، مثلثی، عادی و غیره) مشخص می شوند. با این حال، با توجه به قابل مقایسه بودن پراکندگی آنها، در حال حاضر با 4-5 کمیت تأثیرگذار، قانون توزیع حاصل از خطای اندازه گیری تصادفی در تطابق رضایت بخش با حالت عادی است (شکل 2-1).
تابع توزیع نرمال

و چگالی احتمال
![]()
پراکندگی مشخص کننده پراکندگی خطای تصادفی نسبت به مرکز توزیع و انحراف استاندارد آن کجاست.
پراکندگی و انحراف معیار دقت اندازه گیری را مشخص می کند: هر چه بیشتر، دقت کمتری داشته باشد. در عمل اندازه گیری، انحراف استاندارد c عمدتاً استفاده می شود، زیرا در واحدهای مشابه با مقدار اندازه گیری شده بیان می شود.

برنج. 2-2. انتگرال احتمال
احتمال وقوع یک خطای تصادفی در محدوده از تا مطابق با فرمول
![]()
اگر یک متغیر تصادفی نرمال شده معرفی کنیم، سمت راست برابری به تابع لاپلاس تبدیل می شود که اغلب انتگرال احتمال نامیده می شود.
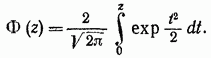
این تابع جدول بندی شده است و مقادیر آن در جدول آورده شده است. و نمودار در شکل نشان داده شده است. 2-2.
اگر احتمال مشخصی داده شود، پس از یافتن آن، می توانید تعیین کنید. بر اساس قانون توزیع نرمال، حداکثر خطای Dmax برابر است، که مربوط به احتمال خطای بیش از حد است، یعنی در 369 مشاهده از 370 مشاهده، با احتمال 0.9973، خطا در بازه ± 3a نهفته است و تنها در یک مشاهده ممکن است از حد خود فراتر رود.

برنج. 2-3. چگالی احتمال خطاهای تصادفی تحت یک قانون توزیع یکنواخت
قانون توزیع یکنواخت نیز در اندازه گیری ها یافت می شود. به طور خاص، برای اندازه گیری مقادیر پیوسته با استفاده از روش شمارش گسسته معمول است. چگالی احتمال خطا در بازه از تا (شکل 2-3) به شکل زیر نوشته شده است.
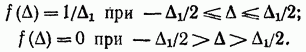
بنابراین، واریانس
و انحراف معیار
![]()
به عنوان مثال، خطای کوانتیزاسیون، که معمولاً در کمترین واحد (از 1/2- تا 1/2) قرار دارد، با انحراف استاندارد مشخص می شود.
به قانون توزیع نرمال برگردیم. این قانون با پارامترهای عددی مشخص می شود: انتظار ریاضی و پراکندگی. تعریف دقیقاین پارامترها عملا غیرممکن هستند، زیرا برای این کار باید تعداد بی نهایت زیادی از مقادیر داشته باشید متغیر تصادفی، یعنی انجام مشاهدات در . در عمل اندازه گیری همیشه متناهی است، بنابراین مقادیر محاسبه شده در نتیجه آزمایش نامیده می شود
برآورد انتظارات ریاضی و انحراف معیار
بیایید روش اندازه گیری آماری یک کمیت خاص را در نظر بگیریم، که مقدار واقعی آن از طریق مشاهدات منفرد ایجاد می شود، در نتیجه تعدادی از مقادیر تصادفی کمیت اندازه گیری شده به دست می آید. در هر یک، خطای مطلق مشاهده 1. تعیین مقدار این خطا غیرممکن است، زیرا ناشناخته است.
میانگین حسابی به عنوان تخمینی از انتظارات ریاضی (مقدار واقعی) در نظر گرفته می شود.
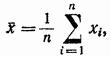
که مقدار واقعی A مقدار اندازه گیری شده در نامیده می شود
اکنون می توانید انحراف مطلق هر نتیجه مشاهده را نسبت به مقدار میانگین محاسبه کنید: بدیهی است که وقتی برای کنترل صحت محاسبات می توانید از خواص انحرافات نتایج مشاهده از میانگین حسابی استفاده کنید: مجموع انحرافات صفر است و مجموع مربع های آنها حداقل است:
برآورد انحراف معیار انحراف مطلق هر یک از مشاهدات منفرد با فرمول تعیین می شود
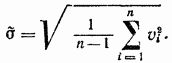
دقت نتیجه اندازه گیری بیشتر خواهد بود. با ارزیابی انحراف استاندارد مقدار میانگین حسابی (واقعی) مشخص می شود:

با افزایش تعداد اندازهگیریها (با نتایج مستقل)، دقت به نسبت افزایش مییابد، به نظر میرسد که با افزایش میتوان هر افزایشی در دقت به دست آورد. با این حال، عقل سلیم و تمرین اندازهگیری نشان میدهد که سود کمی دارد، زیرا خود کمیت اندازهگیری شده ممکن است در طول زمان اندازهگیری تغییر کند.
فاصله اطمینان و احتمال اطمینان.در نتیجه مشاهدات کمیت اندازه گیری شده، برآوردی از مقدار واقعی آن A برابر با میانگین حسابی X مطابق با فرمول (2-11) بدست می آوریم. این تخمین نیز یک متغیر تصادفی است. انحراف استاندارد آن a - با فرمول (2-13) تعیین می شود، یعنی نتیجه اندازه گیری حاوی عدم قطعیت است. باید دریابید که در چه حدودی مقدار واقعی A می تواند در طول اندازه گیری های مکرر یک کمیت (آماری) در شرایط یکسان تغییر کند، یعنی باید فاصله ای از مقادیر را پیدا کنید که با احتمال داده شده، " مقدار واقعی کمیت اندازه گیری شده را پوشش می دهد. چنین فاصله ای را فاصله اطمینان و احتمال معین (تثبیت شده) را فاصله اطمینان می نامند. فاصله اطمینان و احتمال اطمینان مشخص کننده عدم قطعیت نتیجه اندازه گیری است. به صورت تحلیلی این به صورت زیر نوشته شده است:
عبارت (2-14) به این صورت است: مقدار واقعی مقدار اندازه گیری شده در فاصله اطمینان از تا با احتمال اطمینان a قرار می گیرد.
به طور مشابه برای خطای تصادفی
خطای اندازه گیری تصادفی در فاصله اطمینان از تا با احتمال اطمینان a قرار دارد.
بسته به هدف اندازه گیری، احتمال اطمینان برابر با . در عبارات (2-14) و (2-15) فواصل اطمینان متقارن است. نیمی از فاصله اطمینان را حداکثر (حداکثر، مجاز) خطا در احتمال اطمینان a می نامند. گاهی اوقات فاصله اطمینان نامتقارن است و به نظر می رسد
حداکثر خطا و فاصله اطمینان از طریق انحراف استاندارد بیان می شود. برای یک قانون توزیع نرمال، فاصله اطمینان برای یک احتمال اطمینان معین (و بالعکس) با استفاده از جدول انتگرال احتمال (جدول A4) تعیین می شود. احتمال اطمینان تنظیم شده است، برای مثال 0.95. آنها با استفاده از جدول مقداری را پیدا می کنند که در این مورد برابر با 2 است. از آن زمان به بعد فاصله اطمینان
بدیهی است که هم فاصله اطمینان و هم احتمال اطمینان با تعداد مشاهدات مرتبط هستند، زیرا هر چه این فاصله بزرگتر باشد، باریکتر است. با این حال، همانطور که در بالا ذکر شد، در عمل اندازه گیری نادر است. برای تعداد مشاهدات، فاصله اطمینان نه از طریق بلکه از طریق ضریب معینی تعیین می شود که به تعداد مشاهدات و احتمال اطمینان a بستگی دارد. قانون تغییر ضریب توسط توزیع Student متغیر تصادفی نرمال شده محاسبه شده برای با توزیع نرمال تعیین می شود. ضریب با استفاده از فرمول زیر تعیین می شود:
اینها خطاها نیستند، یعنی خطاهای آشکاری نیستند که توسط اپراتور انجام شده است، سپس باید مشخص شود که آیا آنها خطاهای فاحشی هستند که باید از پردازش نیز حذف شوند، مانند اشتباهات. حذف خطاهای فاحش بدون دلیل کافی منجر به بهبود غیر منطقی در نتیجه اندازه گیری می شود. از سوی دیگر، عدم حذف خطای فاحش، به ویژه با تعداد کمی از مشاهدات، هم ارزش واقعی مقدار اندازهگیری شده و هم مرزهای فاصله اطمینان را مخدوش میکند. بنابراین، خطاهای فاحش باید شناسایی و حذف شوند.
ساده ترین راه برای تشخیص یک خطای فاحش تحت قانون توزیع نرمال، مقایسه خطای مطلق یک مشاهده مشکوک با حداکثر خطا است. اگر این نتیجه باید کنار گذاشته شود و مقادیر مجدداً محاسبه شوند. این روش مبتنی است. با توجه به این واقعیت که احتمال انحراف یک مقدار از میانگین حسابی تنها برابر با 0.003 است.
با این حال، باید به خاطر داشت که اگر نه تعداد زیادیمشاهدات، اگرچه با احتمال کم، ممکن است عدد دور ریخته شده یک خطای فاحش نباشد، بلکه یک انحراف آماری طبیعی از یک مقدار معین باشد. بنابراین، در موارد بحرانی، تعیین خطای فاحش بر اساس نظریه احتمال انجام می شود. مشخص شده است که در چه تعداد اندازه گیری با یک احتمال مشخص می توان نتیجه مشاهداتی را که از تعداد معین یا محدودیت های داده شده بیشتر است کنار گذاشت.
خطاهای اندازه گیری به انواع زیر طبقه بندی می شوند:
مطلق و نسبی.
مثبت و منفی.
ثابت و متناسب.
خشن، تصادفی و سیستماتیک.
اشتباه مطلقنتیجه اندازه گیری واحد (A y) به عنوان تفاوت مقادیر زیر تعریف می شود:
آ y = yمن- y ist » yمن -` y.
خطای مربوطهنتیجه اندازه گیری واحد (V y) به عنوان نسبت مقادیر زیر محاسبه می شود:
از این فرمول نتیجه می شود که بزرگی خطای نسبی نه تنها به بزرگی خطای مطلق بستگی دارد، بلکه به مقدار کمیت اندازه گیری شده نیز بستگی دارد. اگر مقدار اندازه گیری شده بدون تغییر باقی بماند ( y) خطای نسبی اندازه گیری را می توان تنها با کاهش خطای مطلق کاهش داد (A y). اگر خطای مطلق اندازه گیری ثابت باشد، می توان از تکنیک افزایش مقدار کمیت اندازه گیری شده برای کاهش خطای نسبی اندازه گیری استفاده کرد.
مثال.فرض کنید ترازوهای تجاری یک فروشگاه دارای خطای مطلق ثابت در اندازه گیری جرم هستند: A m = 10 گرم اگر 100 گرم آب نبات (m 1) را در چنین مقیاسی وزن کنید، خطای نسبی در اندازه گیری جرم آب نبات خواهد بود. :
 .
.
هنگام وزن 500 گرم شیرینی (m2) در همان ترازو، خطای نسبی پنج برابر کمتر خواهد بود:
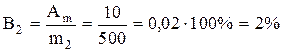 .
.
بنابراین، اگر 100 گرم شیرینی را پنج بار وزن کنید، به دلیل خطا در اندازه گیری جرم، در مجموع 50 گرم محصول از 500 گرم دریافت نمی کنید. وقتی یک بار جرم بزرگتر (500 گرم) را وزن کنید، فقط 10 گرم آب نبات از دست خواهید داد. پنج برابر کمتر
با توجه به موارد فوق می توان به این نکته اشاره کرد که قبل از هر چیز باید در جهت کاهش خطاهای نسبی اندازه گیری تلاش کرد. خطاهای مطلق و نسبی تنها پس از تعیین میانگین قابل محاسبه هستند مقدار حسابینتیجه اندازه گیری
علامت خطا (مثبت یا منفی) با تفاوت بین نتیجه اندازه گیری واحد و واقعی تعیین می شود:
yمن -` y > 0 (خطا مثبت است);
yمن -` y < 0 (خطا منفی است).
اگر خطای مطلق اندازه گیری به مقدار کمیت اندازه گیری شده بستگی نداشته باشد، چنین خطایی نامیده می شود. ثابت. در غیر این صورت خطا خواهد بود متناسب. ماهیت خطای اندازه گیری (ثابت یا متناسب) پس از مطالعات ویژه مشخص می شود.
اشتباه فاحشاندازه گیری (از دست دادن) یک نتیجه اندازه گیری است که به طور قابل توجهی با سایرین متفاوت است، که معمولاً زمانی رخ می دهد که تکنیک اندازه گیری نقض شود. وجود خطاهای اندازه گیری فاحش در نمونه فقط با روش های آمار ریاضی (برای n>2) ثابت می شود. روش های تشخیص خطاهای فاحش را خودتان بشناسید.
تقسیم خطاها به تصادفی و سیستماتیک کاملاً دلخواه است.
به خطاهای تصادفیشامل خطاهایی است که مقدار و علامت ثابتی ندارند. چنین خطاهایی تحت تأثیر عوامل زیر به وجود می آیند: برای محقق ناشناخته. شناخته شده اما غیرقابل تنظیم؛ همواره در حال تغییر.
خطاهای تصادفی تنها پس از اندازه گیری قابل ارزیابی هستند.
ارزیابی کمیمدول خطای اندازه گیری تصادفی می تواند پارامترهای زیر باشد: و غیره.
خطاهای اندازه گیری تصادفی را نمی توان حذف کرد، فقط می توان آنها را کاهش داد. یکی از راه های اصلی برای کاهش بزرگی خطای اندازه گیری تصادفی، افزایش تعداد اندازه گیری های منفرد (افزایش مقدار n) است. این با این واقعیت توضیح داده می شود که بزرگی خطاهای تصادفی با مقدار n نسبت معکوس دارد، به عنوان مثال:
خطاهای سیستماتیک- اینها خطاهایی با بزرگی و علامت بدون تغییر هستند یا طبق یک قانون شناخته شده متفاوت هستند. این خطاها ناشی از عوامل ثابت هستند. خطاهای سیستماتیک را می توان کمی، کاهش و حتی حذف کرد.
خطاهای سیستماتیک به خطاهای نوع I، II و III طبقه بندی می شوند.
به سمت سیستماتیک خطاهای نوع Iبه خطاهای منشأ شناخته شده ای که می توان با محاسبه قبل از اندازه گیری تخمین زد، اشاره کنید. این خطاها را می توان با وارد کردن آنها در نتیجه اندازه گیری در قالب اصلاحات برطرف کرد. نمونه ای از خطاهای این نوع خطا در تعیین تیترومتری غلظت حجمی محلول است اگر تیتر در یک دما تهیه شده باشد و غلظت در دمای دیگر اندازه گیری شود. با دانستن وابستگی چگالی تیترانت به دما، می توان قبل از اندازه گیری، تغییر غلظت حجمی تیترانت را با تغییر دمای آن محاسبه کرد و این تفاوت را می توان به عنوان یک اصلاح در نظر گرفت. نتیجه اندازه گیری
نظام خطاهای نوع دوم- اینها خطاهایی با منشأ شناخته شده هستند که فقط در طی یک آزمایش یا در نتیجه تحقیقات خاص قابل ارزیابی هستند. این نوع خطاها شامل خطاهای ابزاری (دستگاهی)، واکنشی، مرجع و سایر خطاها است. با ویژگی های اینگونه خطاها خودتان در .
هر وسیله ای که در یک روش اندازه گیری استفاده می شود، خطاهای ابزار خود را در نتیجه اندازه گیری وارد می کند. علاوه بر این، برخی از این خطاها تصادفی و بخشی دیگر سیستماتیک هستند. خطاهای تصادفی ابزار به طور جداگانه ارزیابی نمی شوند، آنها به طور کلی با سایر خطاهای اندازه گیری تصادفی ارزیابی می شوند.
هر نمونه از هر دستگاه خطای سیستماتیک شخصی خود را دارد. برای ارزیابی این خطا، انجام مطالعات ویژه ضروری است.
اکثر راه قابل اعتمادارزیابی خطای سیستماتیک ابزار نوع دوم، تأیید عملکرد دستگاه در برابر استانداردها است. برای اندازه گیری ظروف شیشه ای (پیپت، بورت، سیلندر، و غیره)، یک روش خاص انجام می شود - کالیبراسیون.
در عمل، آنچه اغلب مورد نیاز است برآورد نیست، بلکه کاهش یا حذف خطای سیستماتیک نوع دوم است. متداول ترین روش ها برای کاهش خطاهای سیستماتیک هستند روش های نسبی سازی و تصادفی سازی.این روش ها را برای خود در .
به اشتباهات نوع III شامل خطاهایی با منشا ناشناخته است. این خطاها تنها پس از حذف تمام خطاهای سیستماتیک نوع I و II قابل شناسایی هستند.
به سایر خطاهابیایید همه انواع دیگر خطاهایی را که در بالا مورد بحث قرار نگرفته اند (مجاز، خطاهای محدودکننده احتمالی، و غیره) بگنجانیم. مفهوم حداکثر خطای احتمالی در موارد استفاده از ابزار اندازه گیری استفاده می شود و حداکثر مقدار ممکن خطای اندازه گیری ابزاری را فرض می کند (ممکن است مقدار واقعی خطا کمتر از مقدار حداکثر خطای ممکن باشد).
هنگام استفاده از ابزارهای اندازه گیری، می توانید حد مطلق ممکن را محاسبه کنید (P` yو غیره) یا نسبی (E` yو غیره) خطاهای اندازه گیری. بنابراین، برای مثال، حداکثر خطای مطلق اندازهگیری ممکن به صورت مجموع حداکثر تصادفی ممکن (x` y، تصادفی و غیره) و سیستماتیک غیر مستثنی (d` yو غیره) خطاها:
P` y,ex.=x` y، تصادفی و غیره + d` y، و غیره.
برای نمونه های کوچک (n £ 20) ناشناخته جمعیتبا رعایت قانون توزیع نرمال، حداکثر خطاهای اندازه گیری تصادفی ممکن را می توان به صورت زیر تخمین زد:
x` y، تصادفی و غیره = D` y=S` y½t P، n ½،
که در آن t P,n کمیت توزیع دانشجو (معیار) برای احتمال P و حجم نمونه n است. حداکثر خطای مطلق اندازه گیری ممکن در این حالت برابر خواهد بود با:
P` y,ex.= S ` y½t P، n ½+ d` y، و غیره.
اگر نتایج اندازه گیری از قانون توزیع نرمال پیروی نکند، خطاها با استفاده از فرمول های دیگر ارزیابی می شوند.
تعیین مقدار d y،و غیره. بستگی به این دارد که آیا ابزار اندازه گیری دارای کلاس دقت است یا خیر. اگر ابزار اندازه گیری کلاس دقت نداشته باشد، برای مقدار d ` y،و غیره. را می توان پذیرفت حداقل قیمت تقسیم مقیاساندازه گیری . برای یک ابزار اندازه گیری با کلاس دقت شناخته شده برای مقدار d ` yبه عنوان مثال، شما می توانید خطای سیستماتیک مجاز مطلق ابزار اندازه گیری را بگیرید (d y، اضافی):
d` y،و غیره." .
ارزش y، اضافه کردن. بر اساس فرمول های ارائه شده در جدول 5 محاسبه شده است.
برای بسیاری از ابزارهای اندازه گیری، کلاس دقت به شکل اعداد a×10 n نشان داده می شود که a برابر با 1 است. 1.5; 2 2.5; 4 5 6 و n 1 است. 0; -1؛ -2 و غیره که مقدار حداکثر خطای سیستماتیک مجاز ممکن را نشان می دهد (E y، اضافی) و علائم خاص نشان دهنده نوع آن (نسبی، کاهش یافته، ثابت، متناسب).
جدول 5
نمونه هایی از تعیین کلاس های دقت ابزار اندازه گیری
ادامه جدول 5
انتهای جدول 5
اگر نابرابری وجود داشته باشد، می توان از خطاهای سیستماتیک چشم پوشی کرد
در این حالت فرض می شود که:
P` y، و غیره." x` y، مورد و غیره » D` y"S". y½ t P، n ½.
خطاهای تصادفی را می توان نادیده گرفت
برای این مورد P` y، و غیره." d` y،و غیره. .
افزایش تعداد اندازه گیری های منفرد رایج ترین روش کاهش خطاهای تصادفی است (که منجر به هزینه بالاتر اندازه گیری نیز می شود). توصیه می شود n را تا زمانی که کل خطای اندازه گیری تنها با خطای سیستماتیک تعیین شود افزایش دهید. حداقل تعداد اندازهگیریهای موازی مورد نیاز برای این (n دقیقه) فقط زمانی قابل محاسبه است معنی شناخته شدهجمعیت عمومی نتایج منفرد طبق فرمول
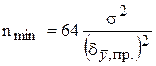 .
.
اگر مولفه های (m تعداد مولفه ها است) خطای سیستماتیک مطلق نتیجه اندازه گیری میانگین حسابی () شناخته شده باشند، می توان آن را با استفاده از فرمول تخمین زد.
 ,
,
که در آن k ضریبی است که با احتمال P و عدد m تعیین می شود.
ارزیابی خطاهای اندازه گیری نه تنها به ابزار اندازه گیری و حجم نمونه بستگی دارد، بلکه به نوع اندازه گیری (اندازه گیری مستقیم یا غیر مستقیم) نیز بستگی دارد.
تقسیم اندازه گیری ها به مستقیم و غیر مستقیم کاملاً دلخواه است. در آینده، تحت اندازه گیری های مستقیمهنگامی که نتیجه اندازه گیری مستقیماً به دست آید، به عنوان مثال، از مقیاس یک ابزار خوانده شود، آنها را درک خواهیم کرد. به اندازه گیری های غیر مستقیمما در هنگام نتیجه اندازه گیری به آنها اشاره خواهیم کرد محاسبه شدبه عنوان تابع (j) از نتایج یک یا چند اندازه گیری مستقیم ( ایکس 1 , ایکس 2 , …, ایکس j،. ...، ایکسک).
باید بدانید که خطاهای اندازه گیری های غیر مستقیم همیشه بیشتر از خطاهای اندازه گیری های مستقیم فردی است. خطاهای اندازه گیری غیرمستقیم طبق قوانین مربوطه ارزیابی می شود.
خطاهای تصادفی منجر به این واقعیت می شود که مقادیر مشاهده شده کمیت اندازه گیری شده در طول اندازه گیری های مکرر به طور تصادفی در اطراف مقدار واقعی آن پراکنده می شوند. سپس مقدار واقعی به عنوان محتملترین مقدار از یک سری آزمایش پیدا میشود و خطا با عرض بازه مشخص میشود که با یک احتمال معین شامل مقدار واقعی میشود. توجیه ریاضی برای این مفاد در نظریه احتمال داده شده است، که کاربرد آن برای پردازش نتایج اندازه گیری در ادبیات و کاربرد مستقیم آن در آثار ارائه شده است. کارگاه فیزیکیدر ادبیات .
اغلب دانش آموزان و دانش آموزان با استفاده از فرمول خطای اندازه گیری را پیدا می کنند
![]() , (6.2)
, (6.2)
که در آن مقدار متوسط به دست آمده در طول فرآیند اندازه گیری است و مقداری است که از کتاب مرجع گرفته شده یا از مفاهیم نظری محاسبه می شود. این تعریف از خطا یک اشتباه فاحش است، زیرا هدف آزمایش، همانطور که در بالا نشان داده شد، آزمایش مفاهیم نظری و شفاف سازی داده های جدولی است.
علاوه بر این، خطا اغلب به عنوان مقدار متوسط انحرافات اندازه گیری فردی از مقدار متوسط طبق فرمول محاسبه می شود.
![]() . (6.3)
. (6.3)
طبق این رویکرد، هر مقدار خطا به همان اندازه ظاهر می شود، یعنی. خطاهای با بزرگی های مختلف به همان اندازه محتمل در نظر گرفته می شوند. این روش را می توان در کار آزمایشگاهیبا تعداد کمی اندازه گیری
با این حال، خطاهای تصادفی به همان اندازه محتمل نیستند. آنها برای تعیین آنها به پردازش آماری نتایج اندازه گیری نیاز دارند. بنابراین توجه به محتوای پردازش آماری نتایج اندازه گیری ضروری به نظر می رسد. تئوری آماری خطاها بر اساس اصول زیر است:
1) با تعداد زیادی اندازه گیری، خطاهای تصادفی با همان اندازه مشاهده می شود، اما علامت متفاوت، یعنی خطاها، چه رو به پایین و چه به سمت بالا، اغلب به یک اندازه رخ می دهند.
2) خطاهای بزرگ (در مقدار مطلق) کمتر از خطاهای کوچک رایج هستند، یعنی. احتمال خطا با افزایش بزرگی خطا کاهش می یابد.
3) خطاهای اندازه گیری می توانند یک سری مقادیر پیوسته به خود بگیرند.
توزیع یک متغیر تصادفی که از ویژگی های فهرست شده تبعیت می کند، توزیع نرمال نامیده می شود. برای تخمین اسپرد شخصیمقادیر یک متغیر تصادفی با توزیع نرمال یا نمونه های منفرد در تئوری توزیع نرمال انتخاب می شوند انحراف استاندارد نمونه نمونه ها،که با فرمول محاسبه می شود:
 . (6.4)
. (6.4)
تخمین مقدار خطای یک اندازه گیری که با فرمول (6.4) تعیین می شود، بسیار مهم است. با این حال، برای اندازه گیری، یک کار مهم این است که تعیین کنیم با چه دقتی مقدار متوسط مقدار اندازه گیری شده با مقدار مورد نظر مطابقت دارد. این مشکل به این دلیل به وجود می آید که می توان میانگین را از ابعاد مختلف. به عنوان مثال، مقدار متوسط را می توان از تعداد متفاوتی از اندازه گیری ها به دست آورد. بنابراین، میانگین تجربی نیز یک متغیر تصادفی است که می تواند با یک تابع توزیع نیز توصیف شود. مقدار انحراف استاندارد مربوط به این تابع همانطور که در نظریه احتمال نشان داده شده است با فرمول تعیین می شود:
 (6.5)
(6.5)
این مقدار نامیده می شود نمونه انحراف معیار میانگینیا خطای استاندارد.
همانطور که از فرمول خطای استاندارد (6.5) مشاهده می شود، با افزایش تعداد اندازه گیری ها کاهش می یابد و دقت نتیجه افزایش می یابد که با استدلال قبلی مطابقت دارد.
فرمول های مورد بحث در بالا برای تعیین خطای اندازه گیری از ویژگی های توزیع نرمال یک متغیر تصادفی استفاده می کنند. با این حال، مشخص نیست که نتایج اندازه گیری بر اساس چه قانونی توزیع می شود. بنابراین، این برآوردها تقریبی است. در این راستا، نیاز به تحلیل این رویکرد برای تعیین خطای اندازه گیری وجود دارد. برای چنین تحلیلی، می توانید از مفهوم فاصله اطمینان، شناخته شده در نظریه احتمال استفاده کنید. اجازه دهید مقدار برابر با احتمالی باشد که نتیجه اندازه گیری - مقدار متوسط - با مقدار واقعی با مقداری بیشتر از . در نظریه احتمال، این عبارت به صورت زیر نوشته می شود:
کمیت نامیده می شود احتمال اطمینان (قابلیت اطمینان)نتیجه یک سری مشاهدات این احتمال را نشان می دهد که فاصله اطمینان شامل مقدار واقعی مقدار اندازه گیری شده است.
فاصله اطمینانفاصله ای از مقادیر نامیده می شود که با درجه اطمینان معینی، مقدار واقعی کمیت اندازه گیری شده را شامل می شود. نمایش هندسی این فاصله در شکل 1 آورده شده است.
بنابراین، برای تعیین خطای تصادفی، باید دو عدد را پیدا یا تنظیم کرد: یعنی مقدار خود خطای تصادفی یا فاصله اطمینان و مقدار احتمال اطمینان.
برای هر مقدار فاصله اطمینان، یک احتمال اطمینان را می توان محاسبه کرد. برای این کار از تابع لاپلاس استفاده می شود که به آن انتگرال احتمال نیز می گویند. تابع لاپلاس به شکل زیر است:
![]() ,
,
جایی که . اغلب هنگام حل مسائل، از مقادیر جدولی تابع لاپلاس استفاده می شود. این مقادیر در جدول 1 نشان داده شده است.
نتایج این جدول نشان می دهد که میانگین مربعات خطا با احتمال اطمینان 0.68، میانگین مربع خطای دو برابر با احتمال اطمینان 0.95 و میانگین مربع خطا سه برابر با احتمال اطمینان 0.997 مطابقت دارد.
میز 1
احتمالات اعتماد به نفس
برای فاصله اطمینان بیان شده به عنوان کسری از میانگین مربع خطا . تابع لاپلاس ![]()
| 1,2 | 0,77 | 2,6 | 0,990 | ||
| 0,05 | 0,04 | 1,3 | 0,80 | 2,7 | 0,993 |
| 0,1 | 0,08 | 1,4 | 0,84 | 2,8 | 0,995 |
| 0.15 | 0,12 | 1,5 | 0,87 | 2,9 | 0,996 |
| 0,2 | 0,16 | 1,6 | 0,89 | 3,0 | 0,997 |
| 0,3 | 0,24 | 1,7 | 0,91 | 3,1 | 0,9981 |
| 0,4 | 0,31 | 1,8 | 0,93 | 3,2 | 0,9986 |
| 0,5 | 0,38 | 1,9 | 0,94 | 3,3 | 0,9990 |
| 0,6 | 0,45 | 2,0 | 0,95 | 3,4 | 0,9993 |
| 0,7 | 0,51 | 2,1 | 0,964 | 3,5 | 0,9995 |
| 0,8 | 0,57 | 2,2 | 0,972 | 3,6 | 0,9997 |
| 0,9 | 0,63 | 2,3 | 0,978 | 3,7 | 0,9998 |
| 1,0 | 0,68 | 2,4 | 0,984 | 3,8 | 0,99986 |
| 1.1 | 0,73 | 2,5 | 0,988 | 3,9 | 0,99990 |
| 4,0 | 0,99993 |
خطای تصادفیمعمولاً به عنوان نصف عرض فاصله اطمینان تعریف می شود. اندازه فاصله اطمینان به عنوان مضربی از انحراف استاندارد نمونه از مقدار میانگین مشخص می شود ، که با فرمول (6.5) تعیین می شود.سپس خطای تصادفی اندازه گیری های مکرربا فرمول تعیین می شود.